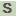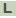>AZC_1598 para-aminobenzoate synthase
MLRHAVESPQPGDAPPVHVVPIAYGDPVRLFRAFADDPMAALLHSAAQDGARGRYSYIAA
EPFRVIVADADGVRVDGASVAGDPFTVLGAQLAACPAPEGLAPVPFAGGAVGFLGYELGR
HVERLPPPKPGLPIPHMVMGLYDVVIAFDHAARAAVLISTGLPEIAANVRAARAKARVAH
LLARLSKAPAEDTPPDITARADWTAELSRAEMEARIGRTVDYIHAGDIFQANITQRFLSR
RPEGLSDYDLYRRLTALSPAPFSALLVCGPDLALMSASPERFLKVAPDGGVETRPIKGTR
PRGGTTAEDTALAAALLASEKDRAENLMIVDLMRNDLGRVSRLGSVTVPALCALETFASV
HHLVSEVRSVLAPGRGPVDLLRACFPGGSITGAPKVRAMEIIHELEPAPRGPYCGSVAWI
GFDGAMDSSIVIRTLVRAGETLVAQAGGGIVADSDPAAEYEESLVKVAPLLKAAAGETP
>AZC_1598 para-aminobenzoate synthase
ATGTTACGGCACGCGGTGGAATCGCCGCAGCCCGGAGATGCCCCGCCCGTGCACGTGGTC
CCCATCGCCTATGGCGATCCCGTCCGCCTGTTCCGAGCCTTTGCGGACGACCCCATGGCC
GCCCTGCTGCACAGCGCGGCGCAGGATGGCGCGCGCGGGCGCTATTCCTACATCGCCGCC
GAACCTTTCCGGGTCATCGTCGCGGACGCCGACGGCGTGCGGGTGGACGGCGCGTCGGTG
GCGGGCGATCCGTTCACCGTTCTGGGCGCGCAGCTCGCCGCCTGTCCGGCACCCGAGGGG
CTTGCGCCCGTGCCGTTCGCCGGCGGCGCGGTCGGTTTCCTCGGTTATGAGCTGGGTCGG
CATGTGGAGCGCCTGCCGCCGCCGAAGCCGGGGCTGCCCATCCCCCACATGGTGATGGGC
CTCTATGACGTGGTGATCGCCTTCGATCATGCGGCGCGGGCGGCCGTCCTGATCTCCACC
GGCCTGCCGGAGATAGCGGCGAACGTTCGCGCGGCACGGGCCAAGGCGCGGGTCGCGCAT
CTCCTCGCCCGCCTCTCGAAGGCGCCGGCCGAGGACACGCCGCCGGACATCACAGCCCGC
GCGGACTGGACGGCAGAACTCTCGCGCGCCGAGATGGAGGCCCGCATCGGCCGCACGGTG
GACTACATCCACGCGGGCGACATCTTCCAGGCCAACATCACCCAGCGCTTCCTGAGCCGC
CGCCCGGAGGGCCTGTCCGATTACGACCTTTACCGGCGGCTGACCGCCCTCTCGCCCGCC
CCCTTCTCGGCCCTGCTCGTCTGCGGACCGGACCTTGCCCTCATGAGCGCCTCGCCCGAG
CGCTTCCTGAAGGTGGCGCCCGATGGCGGCGTGGAGACGCGGCCCATCAAGGGCACCCGG
CCGCGCGGCGGCACGACGGCCGAGGACACGGCCCTCGCCGCCGCGCTTCTCGCCAGCGAG
AAGGACCGGGCCGAGAATCTGATGATCGTGGACCTCATGCGCAACGATCTCGGCCGTGTG
TCACGGCTCGGCAGCGTCACCGTGCCGGCGCTCTGCGCGCTGGAGACCTTTGCCAGCGTG
CATCACCTCGTCTCCGAGGTGCGGAGCGTCCTTGCCCCCGGCCGCGGGCCGGTGGACCTG
CTGCGGGCCTGTTTCCCCGGCGGCTCCATCACTGGGGCGCCCAAGGTGCGGGCCATGGAG
ATCATCCACGAACTGGAGCCCGCGCCGCGCGGGCCCTATTGCGGGAGCGTGGCGTGGATC
GGCTTTGACGGCGCCATGGATTCCTCCATCGTCATCCGCACGCTGGTGCGCGCGGGCGAA
ACCCTGGTGGCGCAGGCGGGCGGCGGCATCGTCGCCGACAGCGACCCAGCGGCGGAATAT
GAGGAGAGCCTGGTGAAAGTGGCGCCCCTGCTGAAGGCGGCTGCGGGAGAGACGCCATGA