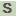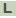>Svir_20250 benzaldehyde dehydrogenase (NAD+)
VTASTAGPVGDSPTRWSSSAATGGTLTVTAPATGSVLAEVDAASPADVDRAVAKAKQAQR
DWAATTYDQRAAVLRRAARLLEADPDRLRRWLVPESGSAMGKASFEVGLVVSELDECAAL
ASHPYGELLHSTKPRLSLARRVPVGVVGVISPFNFPGILSMRSVAPALAVGNAVVLKPDP
RTPISGGLALAELLAEAGLPDGLLTVLPGGAEVGQALVAHPDVPCISFTGSTPAGRKIAE
AAAPLLKRVHLELGGNNALLVLPDADVEAAASAAAWGSFLHQGQICMTAGRHLVHSSIAD
EFTALLAKKAEAITVGDPTDENNALGPIIDERQREQIHRIVTDTVDAGAKLLAGGKYDGL
FYRPTVLGNVPVDSPAFRQEIFGPVAPVVTYDTVDEAIELINDSEFGLSVGILTSDAFRA
YELADRIESGMVHINDQTVDDEATIPFGGVKASGAGGRFGGARANLESFTEIQWITMQSS
IERYPF
>Svir_20250 benzaldehyde dehydrogenase (NAD+)
GTGACAGCTAGTACAGCCGGTCCGGTCGGTGACAGCCCCACTCGCTGGTCTTCCTCGGCG
GCCACGGGCGGTACTTTGACGGTGACGGCGCCTGCCACGGGCAGTGTCCTCGCCGAGGTC
GACGCGGCTTCCCCCGCCGATGTCGACCGTGCCGTCGCCAAGGCGAAGCAGGCCCAGCGG
GACTGGGCCGCCACCACCTACGACCAGCGCGCCGCGGTGCTGCGGCGGGCCGCTCGACTG
TTGGAAGCCGACCCCGACCGGTTGCGCCGTTGGCTCGTCCCCGAATCGGGTTCGGCGATG
GGCAAGGCGTCGTTCGAGGTCGGCCTGGTGGTCTCGGAACTCGACGAATGCGCGGCGCTG
GCCTCTCATCCCTACGGTGAACTGCTGCACTCCACCAAACCGCGCCTGTCGCTGGCACGT
CGCGTACCGGTCGGCGTGGTGGGGGTGATCTCGCCGTTCAACTTCCCCGGAATCCTGTCG
ATGCGGTCCGTCGCGCCCGCGTTGGCGGTGGGCAACGCCGTGGTGTTGAAACCCGATCCC
CGCACGCCGATCTCGGGTGGTCTCGCGCTCGCCGAGCTGCTCGCCGAGGCGGGGTTGCCC
GACGGGTTGCTCACCGTGTTGCCCGGCGGCGCGGAGGTCGGACAGGCGCTGGTGGCCCAC
CCCGACGTGCCGTGCATCTCGTTCACCGGATCCACCCCGGCCGGACGCAAGATCGCGGAG
GCCGCCGCGCCGCTGCTCAAGCGCGTGCACCTGGAACTCGGGGGCAACAACGCACTACTC
GTGCTCCCGGACGCCGACGTCGAAGCCGCCGCCTCGGCCGCCGCGTGGGGTTCGTTCCTG
CACCAGGGACAGATCTGCATGACGGCGGGGCGGCACCTCGTGCACTCGTCGATCGCGGAC
GAGTTCACGGCGTTGCTCGCGAAGAAGGCCGAGGCCATCACCGTCGGAGACCCGACGGAC
GAGAACAACGCACTCGGCCCGATCATCGACGAACGGCAGCGGGAGCAGATCCACCGCATC
GTGACCGACACGGTGGACGCGGGCGCGAAACTGCTCGCCGGAGGGAAGTACGACGGCCTG
TTCTACCGGCCGACGGTCCTGGGGAACGTCCCGGTCGACAGCCCGGCGTTCCGGCAGGAG
ATCTTCGGTCCGGTGGCCCCCGTGGTCACGTACGACACCGTGGACGAGGCGATCGAGCTC
ATCAACGACAGCGAGTTCGGCCTCAGCGTCGGCATCCTGACCTCCGACGCGTTCCGGGCA
TACGAGCTCGCGGACCGGATCGAGTCGGGCATGGTCCACATCAACGACCAGACGGTCGAC
GACGAGGCCACGATCCCGTTCGGTGGCGTGAAGGCCTCCGGGGCGGGCGGCCGCTTCGGT
GGTGCGCGGGCCAACCTGGAGTCGTTCACCGAGATCCAGTGGATCACGATGCAGTCGTCG
ATCGAGCGTTATCCGTTCTGA