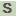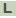>SCAT_1146 conserved exported protein of unknown function
MTTPATAPGPSRRTLLATTALAGLGTALTPATGHAATPRTTPGLAVLRSAALDVTVDTAF
PRVVSFTDRATGAVLHGHPAPVTTLLVDGVTHTPRVTATPGTDRVDYTLTLDGGTRIEAG
ITVDGMRVTFRVTAVHEAPGHLVGTLQLPGQAWLSVRGDQPGATVLTARLQLDKAKNGDT
TVTVTDATPADPAPVGCAYAVAAHDTLAAAVEANTVWDDVTANPAAAWENGRFWRQAVRD
GDGHTRVGISCGQWTHRGAGAAPDDTEPLPYVTVVLTRDRNGDGRIDWQDAAIALRDIMV
DPLGADDQHLRVVPHIPFNFASQATNPFAATLDNVKRIALATDGLRQFTLLKGYQSEGHD
SAHPDYAGNYNERAGGLAGLNALLAAGTTWNSDFAVHVNATESYPVAHAFSETLVDKDDP
QWDWLDQSYRINSRRDLASHDIVRRFRRLREETHPALDTVYLDVFRESGWTSDGLQRHLR
AQGWKVASEWGHGLERSSLWSHWANETDYGPDTSRGVNSTLIRFLRNHQKDVFADKFPLL
GTAKLGTFEGWQGKTDWHAFHRLLWTDNLPAKYLQAYPVKTWSDHEITFFGPTATSVCDT
TGRRVITTDGRTVYDGGTYLLPWEPRAATDPARLYHYNPAGGTTGWRLPRGWAGARTVHL
YRLTDTGRRHVAEVPVRDGAVTLTADAGVPYAVYRRPAPPLSDPRWGEGTPVHDPGFNSG
SLRGWQVTGPARVVRDELGDPELVIGPGGPARVRQRLARLTPGDYVASVQVEVGERPGER
RRAALEIGTADGVTAVNWTDTSTAGNYIAADRKHGTRFQRMFTRFRVPSGGGPVTLALTA
DAGTARVRFDNVRVVPTAPAPPLPEHVLLHEDFEHVPQGWGPFVKGPAGGANDPRTHIAQ
RHFPYTQRGWNGKAIDDVVDGTQSLKSRGESTGVVYRTVPHTARFRPGRRYRVSLRYENE
RAGQYAWITAVDVPGAAAPTVLATLPLPVATGPTTLTYEFTAPVEGETWVGLSKTGGDEV
AEFTLDTVTLALAASH
>SCAT_1146 conserved exported protein of unknown function
ATGACCACCCCCGCCACCGCCCCCGGACCCAGCCGCCGCACCCTGCTGGCCACCACGGCA
CTCGCCGGCCTGGGGACCGCGCTCACCCCGGCCACCGGACACGCCGCCACCCCCAGGACC
ACCCCGGGCCTGGCGGTGCTGCGCTCGGCCGCGCTCGACGTCACCGTCGACACCGCCTTC
CCCCGCGTCGTCTCGTTCACCGACCGCGCCACCGGAGCCGTACTCCACGGCCACCCCGCC
CCGGTCACCACACTCCTGGTCGACGGCGTCACCCACACCCCGCGGGTCACCGCCACCCCG
GGCACCGACCGCGTCGACTACACCCTCACCCTCGACGGCGGCACCCGTATCGAGGCCGGG
ATCACCGTGGACGGCATGCGCGTCACCTTCCGCGTCACCGCCGTCCACGAAGCCCCCGGC
CACCTCGTCGGCACCCTCCAACTGCCCGGCCAGGCATGGCTGAGCGTCCGCGGCGACCAG
CCCGGCGCCACCGTGCTCACCGCACGGCTCCAGCTCGACAAGGCGAAGAACGGCGACACC
ACCGTCACCGTCACCGACGCCACCCCGGCCGACCCCGCCCCCGTCGGCTGCGCCTACGCG
GTGGCCGCCCACGACACCCTCGCCGCCGCGGTCGAGGCCAACACCGTATGGGACGACGTC
ACCGCCAACCCGGCCGCCGCCTGGGAGAACGGCCGCTTCTGGCGCCAGGCGGTACGCGAC
GGCGACGGACATACCCGGGTCGGCATCTCCTGCGGCCAGTGGACCCACCGCGGCGCCGGC
GCCGCCCCTGACGACACCGAACCGCTGCCCTACGTCACCGTCGTCCTCACCCGCGACCGC
AACGGCGACGGCCGCATCGACTGGCAGGACGCCGCCATCGCCCTGCGCGACATCATGGTC
GACCCGCTCGGCGCCGACGACCAGCACCTGCGCGTCGTCCCGCACATCCCGTTCAACTTC
GCCAGCCAGGCCACCAACCCGTTCGCCGCCACCCTCGACAACGTCAAACGCATCGCCCTG
GCCACCGACGGACTACGCCAGTTCACCCTGCTCAAGGGGTACCAGTCGGAAGGCCACGAC
TCCGCCCACCCCGACTACGCCGGCAACTACAACGAACGCGCCGGCGGCCTGGCCGGCCTC
AACGCCCTGCTCGCCGCCGGCACCACCTGGAACAGCGACTTCGCCGTACACGTCAACGCC
ACCGAGTCCTACCCGGTCGCCCACGCCTTCTCCGAGACCCTGGTCGACAAGGACGACCCC
CAGTGGGACTGGCTCGACCAGAGCTACCGCATCAACTCCCGCCGCGACCTGGCCTCCCAC
GACATCGTGCGCCGCTTCCGACGGCTGCGCGAGGAGACCCACCCCGCCCTCGACACCGTC
TACCTCGACGTCTTCCGGGAGAGCGGCTGGACCTCCGACGGCCTCCAACGCCATCTGCGC
GCCCAGGGCTGGAAGGTGGCCAGCGAATGGGGACACGGACTGGAACGCTCCTCCCTCTGG
TCGCACTGGGCCAACGAGACCGACTACGGCCCCGACACCTCACGCGGCGTCAACTCCACC
CTCATCCGCTTCCTGCGCAACCACCAGAAGGACGTCTTCGCCGACAAGTTCCCCCTGCTC
GGCACGGCCAAGCTCGGCACCTTCGAAGGCTGGCAGGGCAAGACCGACTGGCACGCCTTC
CACCGCCTGCTGTGGACCGACAACCTGCCCGCCAAATACCTCCAGGCCTACCCCGTCAAG
ACCTGGTCCGACCACGAGATCACCTTCTTCGGACCCACCGCCACCTCGGTCTGCGACACC
ACCGGCCGCCGCGTCATCACCACCGACGGCCGCACCGTCTACGACGGCGGCACCTACCTG
CTGCCCTGGGAACCCCGCGCAGCGACCGACCCGGCCAGGCTCTACCACTACAACCCGGCC
GGCGGCACCACCGGCTGGCGGCTGCCCCGCGGCTGGGCCGGCGCCCGCACCGTCCACCTG
TACCGGCTCACCGACACCGGCCGGCGGCACGTCGCCGAGGTCCCGGTGCGCGACGGCGCA
GTCACCCTCACCGCCGACGCCGGGGTGCCCTACGCCGTCTACCGGCGGCCCGCCCCGCCG
CTGAGCGACCCGCGCTGGGGCGAGGGCACCCCGGTGCACGACCCCGGCTTCAACTCCGGC
TCCCTGCGCGGCTGGCAGGTCACCGGCCCGGCCCGCGTGGTACGCGACGAACTCGGCGAC
CCCGAACTCGTCATCGGCCCCGGCGGCCCGGCCCGCGTCCGGCAGCGGCTCGCCCGGCTC
ACCCCCGGCGACTACGTGGCCTCCGTCCAGGTGGAGGTCGGCGAACGGCCCGGGGAACGG
CGCCGGGCCGCCCTGGAGATAGGCACCGCCGACGGCGTCACCGCCGTCAACTGGACCGAC
ACCTCCACCGCCGGGAACTACATCGCCGCCGACCGCAAACACGGCACCCGCTTCCAGCGC
ATGTTCACCCGCTTCCGGGTGCCGTCCGGCGGCGGTCCGGTCACCCTCGCGCTCACCGCC
GACGCCGGCACCGCCCGCGTCCGCTTCGACAACGTACGGGTCGTCCCCACGGCGCCCGCC
CCGCCACTGCCCGAACACGTCCTCCTCCACGAGGACTTCGAACACGTCCCGCAGGGCTGG
GGCCCCTTCGTCAAAGGCCCCGCCGGCGGCGCCAACGACCCACGCACCCACATCGCCCAA
CGCCACTTCCCCTACACCCAGCGCGGCTGGAACGGCAAGGCGATCGACGACGTCGTCGAC
GGCACGCAGTCGCTGAAGTCCCGCGGCGAGAGCACCGGCGTTGTGTACCGCACCGTGCCG
CACACCGCGCGGTTCCGTCCCGGGCGCCGCTACCGGGTCTCCCTGCGGTACGAGAACGAA
CGCGCCGGCCAGTACGCCTGGATCACCGCCGTCGACGTCCCCGGCGCCGCCGCCCCCACC
GTCCTGGCCACCCTCCCCCTCCCGGTGGCCACCGGGCCCACCACCCTCACCTACGAGTTC
ACCGCCCCGGTGGAGGGGGAGACGTGGGTGGGGCTGAGCAAGACGGGCGGGGACGAGGTG
GCGGAGTTCACCCTCGACACGGTCACGCTCGCGCTGGCGGCCAGCCATTGA