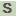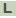>SCLAV_1212 Putative membrane protein
MTRDARRPTGARRRTSVHPADGGPSRRTVVAATALAGAGTALATGGQAAAAPGPRALLRS
AALDVQVDRAFPSVVSYTDRATGAVLHGQDEPVTSVLIDAVAHVPDRVALRTRRDRARYT
LGFGPTEIDVEIRVTGATVHWRVTRIADTAALRIGTLEIPSLALLSVRADQPGAVLYGAR
VHLDKAGDGDTLIEVGPATPVEERPTGCAYAVVAHDGLGGAIETNTVWDKPSAAAGTTWE
NGRLWRQVTVRDGVVTARLVPGQWTHRAATAPVEQTEPLPYATVVVTGDRNGDGVVDWQD
AAIAFRDIMVEPLGADEQHLRVVPHIPFNFASQATNPFLATLDQVKRISLATDGLRQYTL
LKGYQSEGHDSAHPDYAGNHNRRAGGLDDLNTLLREGRKWNSDFGVHVNCTESYPVANAF
SETLVDKDNEQWDWLDQSYRIDQRRDLVSGEVIRRFAALRAETDPALNTLYIDVFRESGW
TSDRLQRALREQGWQITTEWGHGLERSALWAHWATETDYGPDSSRGVNSRLIRFIRNHQK
DVFADKWPTLLGIPRTGNFEGWVGKTDWTVFYRLIWTESLPAKYLQAHPVKRWTDHEIAF
FGPGATSVTDTDGVRTIVTDGRTVYEGGRYLLPWEPRRALDPPKLYHYNPEGGATTWRLP
RGWAGRPAVALYRLTDQGRVFERTLPVRSGRITVDAAADQPYVLYRSRPAPLPDPRWGQG
TPLHDPGFSSGSLDGWHTSGPVSVVRSAIGDHELVMAAGAAGTAGQRLRRLAPGGYAASV
QVEVGERAGERRRASLEVRTADGVRAVNWTDISTAVNQVAADRKHGTRFQRMFTWFTVPE
GGGPVVLTLRAEAGGARVRFDNVRVVPGTRTPAPGTVAHEDFENVPQGWGVFVKGDAGGV
TDPRTHIAQRNAPYTQRGWNGKAIDDVVDGTESLKSRGENEGLVYRTVQHLVRFEPGRRY
RVAFRYQNERADQYAWVTGVDDREQDRVPLPVATSPTLWTHEFTAPAEGESWVGLRKTGG
AWGAEFVLDSFEVREV
>SCLAV_1212 Putative membrane protein
ATGACACGTGACGCCCGTCGGCCGACCGGAGCCCGGAGGAGGACGAGCGTGCACCCAGCA
GACGGCGGCCCCAGCCGCAGGACCGTCGTGGCGGCGACCGCCCTGGCCGGGGCGGGTACC
GCGCTCGCCACCGGCGGGCAGGCCGCCGCCGCCCCCGGCCCCCGGGCCCTGCTCCGCTCC
GCCGCCCTCGACGTCCAGGTGGACCGGGCCTTCCCCAGCGTCGTCTCGTACACCGACCGC
GCCACCGGGGCGGTCCTGCACGGGCAGGACGAGCCCGTCACCTCCGTACTGATCGACGCG
GTCGCCCACGTCCCCGACCGGGTCGCGCTGCGGACCCGCCGCGACCGCGCCCGTTACACC
CTCGGCTTCGGCCCCACCGAGATCGACGTCGAGATACGGGTGACGGGAGCCACCGTCCAC
TGGCGGGTCACCCGGATCGCCGACACCGCCGCCCTGCGGATCGGCACCCTGGAGATACCC
TCGCTCGCCCTGCTCTCCGTCCGCGCCGACCAGCCCGGCGCGGTCCTGTACGGGGCCCGC
GTCCACCTGGACAAGGCGGGCGACGGCGACACCCTCATCGAGGTGGGCCCCGCGACCCCC
GTCGAGGAGCGGCCCACCGGCTGCGCGTACGCCGTCGTCGCCCACGACGGGCTCGGCGGC
GCGATCGAGACCAACACCGTCTGGGACAAGCCCTCCGCCGCCGCCGGTACCACCTGGGAG
AACGGCAGGCTCTGGCGGCAGGTCACGGTCCGGGACGGGGTGGTCACGGCCCGGCTGGTC
CCCGGCCAGTGGACCCACCGCGCCGCCACCGCCCCCGTGGAGCAGACCGAGCCGCTGCCG
TACGCCACCGTCGTCGTCACCGGCGACCGCAACGGCGACGGCGTCGTGGACTGGCAGGAC
GCCGCCATCGCCTTCCGGGACATCATGGTCGAGCCGCTGGGCGCGGACGAGCAGCATCTG
CGGGTCGTGCCGCACATCCCGTTCAACTTCGCCTCCCAGGCGACCAATCCCTTCCTCGCC
ACCCTCGACCAGGTCAAACGGATCTCCCTGGCGACCGACGGACTGCGGCAGTACACCCTG
CTCAAGGGGTACCAGTCCGAGGGGCACGACTCGGCCCACCCCGACTACGCGGGCAACCAC
AACCGGCGCGCGGGCGGACTCGACGACCTCAACACCCTGCTGCGCGAGGGCCGGAAGTGG
AACAGCGACTTCGGCGTCCATGTCAACTGCACCGAGTCCTACCCCGTCGCGAACGCCTTC
TCCGAGACCCTCGTCGACAAGGACAACGAGCAGTGGGACTGGCTCGACCAGTCGTACCGC
ATCGACCAGCGCCGCGACCTGGTCAGCGGTGAGGTGATCCGGCGCTTCGCCGCGCTGCGG
GCGGAGACCGACCCCGCCCTGAACACGCTCTACATCGATGTCTTCCGGGAGTCGGGCTGG
ACCTCCGACCGGCTCCAGCGGGCGCTGCGCGAGCAGGGCTGGCAGATCACCACCGAGTGG
GGCCACGGCCTGGAGCGCTCGGCGCTGTGGGCGCACTGGGCCACGGAGACCGACTACGGG
CCCGACTCCTCCCGGGGCGTCAACTCCCGGCTGATCCGCTTCATCCGCAACCACCAGAAG
GACGTCTTCGCCGACAAGTGGCCCACCCTGCTCGGCATCCCGCGCACGGGGAACTTCGAG
GGCTGGGTCGGCAAGACCGACTGGACCGTCTTCTACCGGCTGATCTGGACCGAGTCGCTG
CCCGCGAAGTACCTCCAGGCCCACCCCGTCAAGCGGTGGACCGACCACGAGATCGCCTTC
TTCGGGCCCGGCGCGACCTCGGTCACCGACACGGACGGGGTGCGCACGATCGTCACCGAC
GGCCGCACGGTCTACGAGGGCGGCCGGTATCTGCTGCCCTGGGAGCCCCGCCGGGCGCTG
GACCCGCCCAAGCTCTACCACTACAACCCGGAGGGCGGCGCCACCACCTGGCGGCTGCCC
CGGGGCTGGGCGGGCCGCCCGGCGGTCGCCCTGTACCGCCTCACCGACCAGGGCCGGGTC
TTCGAACGGACCCTGCCGGTCCGCTCCGGCCGGATCACCGTCGACGCGGCGGCCGATCAG
CCGTACGTCCTGTACCGCTCCCGCCCGGCGCCCCTGCCCGACCCCCGGTGGGGCCAGGGC
ACCCCGCTGCACGACCCCGGCTTCTCCTCCGGCTCCCTCGACGGCTGGCACACCAGCGGC
CCGGTCTCGGTCGTCCGCAGCGCGATCGGCGACCACGAGCTGGTGATGGCCGCGGGCGCC
GCCGGCACGGCCGGACAGCGGCTGCGCAGGCTCGCCCCCGGCGGCTACGCGGCCTCCGTC
CAGGTCGAGGTGGGGGAGCGGGCGGGCGAGCGGCGCCGCGCGAGCCTGGAGGTGCGCACC
GCCGACGGGGTACGGGCCGTCAACTGGACGGACATCTCCACCGCCGTCAACCAGGTGGCG
GCCGACCGCAAGCACGGCACCCGCTTCCAGCGGATGTTCACCTGGTTCACCGTCCCCGAG
GGCGGCGGCCCCGTCGTCCTCACCCTGCGGGCGGAGGCGGGCGGCGCCCGGGTCCGCTTC
GACAACGTCCGCGTCGTCCCCGGCACCCGCACGCCCGCCCCCGGCACCGTCGCCCACGAG
GACTTCGAGAACGTCCCCCAGGGCTGGGGCGTCTTCGTCAAGGGCGACGCGGGCGGCGTC
ACCGACCCGCGCACCCACATCGCCCAGCGGAACGCCCCGTACACCCAGCGCGGCTGGAAC
GGGAAGGCGATCGACGATGTCGTCGACGGCACCGAATCCCTCAAATCACGCGGTGAGAAC
GAGGGACTGGTCTACCGGACCGTCCAGCACCTGGTCCGCTTCGAGCCGGGGCGGCGCTAC
CGGGTCGCCTTCCGCTACCAGAACGAACGGGCCGACCAGTACGCCTGGGTCACCGGCGTC
GACGACCGCGAACAGGACCGGGTGCCGCTGCCGGTGGCGACCTCGCCGACGCTCTGGACC
CACGAGTTCACCGCACCCGCCGAGGGCGAGAGCTGGGTGGGGCTGCGCAAGACCGGGGGA
GCGTGGGGCGCGGAGTTCGTCCTCGACTCCTTCGAGGTCCGGGAGGTCTGA